You want to put a website on the internet. So far, so simple. But the moment you go looking for how, you fall into a confusing pile of options that all seem to do the same thing at wildly different prices: Squarespace and Shopify and Webflow, but also Heroku and Vercel and Render, but also AWS and Google Cloud, but also some German company renting you a whole physical server for the price of a sandwich, but also — if you read the wrong forum thread at 1am — buying your own servers and putting them in a building.
Here's the thing nobody tells you: these aren't competing products. They're rungs on a single ladder. It's the same website at every rung. The only thing that changes as you climb down is how much of it is your problem instead of someone else's.

At the top, you type words into a box and a company turns them into a running, backed-up, secured, globally-served website. At the bottom, you are personally responsible for a humming metal box, the electricity feeding it, the air conditioning cooling it, and the fiber-optic cable carrying its packets to the world. Everything in between is a different split of that same labor. Once you can see the ladder, the whole confusing market snaps into focus — and so does the only question that actually matters: which rung is right for you?
This essay is going to argue something slightly uncomfortable: that the answer, for almost everyone, is "higher than you think" — and that the loud voices telling you the upper rungs are a "rip-off" are right about the price and wrong about what you're buying. But to get there honestly, we have to walk down the ladder, rung by rung, and be fair to each one.
Part 1It's all one ladder
The rigorous version of "convenience versus control" already exists, and it has a boring name: the shared responsibility model. Every cloud provider publishes one. It's a diagram with a line through it: above the line, the stuff they operate; below the line, the stuff you operate. As you descend the ladder, that line moves down, and your half gets bigger.1
The official taxonomy carves the middle of the ladder into three tiers.2 At the top is Software-as-a-Service — you use an application someone else runs entirely (this is where Squarespace, Wix, and Shopify live; you manage nothing underneath). In the middle is Platform-as-a-Service — you supply your own code and they run it for you, handling the operating system, the servers, the scaling (Heroku, Render, Vercel, Netlify). At the bottom of the formal taxonomy is Infrastructure-as-a-Service — they rent you raw virtual machines and you build everything on top (AWS, Google Cloud, Azure). Below even that, the taxonomy runs out and you're into the physical world: a bare server you rent and administer yourself (Hetzner, DigitalOcean, Vultr), then colocation — your own purchased servers in someone else's building — then, at the very bottom, your own data center, where you own the racks, the power contracts, and the cooling.
If that's a lot of jargon, here's the version that's been making the rounds for a decade, the "Pizza as a Service" analogy: making pizza at home is on-premises (you buy everything, you do everything); take-and-bake is renting infrastructure; delivery is the platform; and dining out is software-as-a-service (you just show up and eat).3 Same pizza. The only variable is how much of the work is yours.
And one honest complication, stated up front so I'm not accused of hiding it later: the ladder is a useful map, not a law of physics. Serverless — AWS Lambda, Cloudflare Workers — doesn't sit neatly on one rung; it's more like an elevator shaft cutting across several, where you hand over a single function and pay per request.4 Real systems also mix rungs all the time: a static site on Vercel, a database on AWS, a batch job on a cheap rented server. The ladder is how you reason about each piece, not a vow you take for your whole stack.
Part 2What each rung does for you (and what it hands back)
Amazon's Jeff Bezos gave the work that the upper rungs absorb a name in the early days of AWS: "undifferentiated heavy lifting." Provisioning servers, patching operating systems, configuring load balancers, setting up backups — none of it makes your website yours, none of it is the thing your visitors came for, and all of it has to be done correctly anyway. The higher rungs do it for you. The lower rungs hand it back.5

Picture the same person at three rungs. At the top, they're holding a laptop, and that's it — they type, they click, the site is live, secured, and backed up by dinner. Drop to the cloud, and now they're carrying a server they have to configure and a pager that goes off when it misbehaves. Drop to the bottom, and they're buried under the whole pile: the metal, the patching, the security, the backups, the power, the cooling — and the pager never stops. Convenience and control are not two things. They're one dial, and turning it toward "I control everything" is identical to turning it toward "everything is my job."
This is why "which rung is best" is a malformed question. A rung isn't good or bad; it's a trade, and the trade is only good or bad relative to what you're trying to do and who you are. To see why the trade flips, follow the money.
Part 3The money flips
Here's the part that surprises people. The upper rungs are cheaper to start and more expensive at scale. The lower rungs are more expensive to start and cheaper at scale. The two cost curves cross.
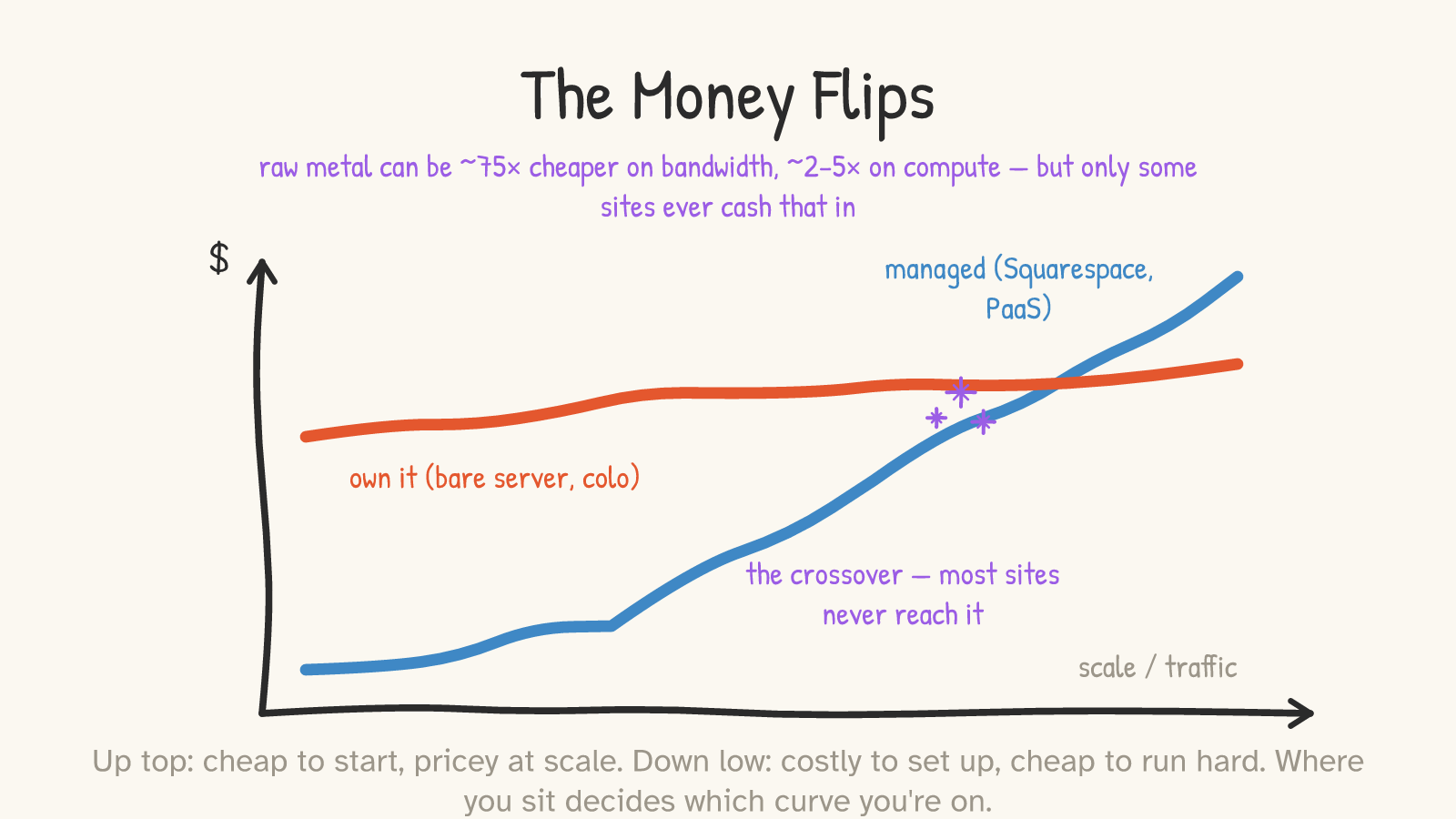
Up top, you can have a real site for the price of a couple of lunches a month, and you pay nothing to "set it up" because there's nothing to set up. But you pay a convenience tax on everything that grows: Shopify's monthly fee climbs from $29 to about $2,300 as you scale, and if you don't route payments through Shopify's own system it adds up to a 2% surcharge on every sale — on top of ordinary card-processing fees.6 Down at the bottom, the raw materials are startlingly cheap. The German host Hetzner will rent you a capable cloud server for a few euros a month, and — the number that launches a thousand forum arguments — its raw bandwidth is roughly 75 times cheaper than the equivalent on AWS.7
That 75× is real, and I want to be precise about what it is and isn't. It's specifically the price of egress — data sent out to the internet — and it compares Hetzner's overage rate to AWS's, not two equivalent bundles: AWS's price includes a global CDN, contractual SLAs, and multi-region redundancy that a single Hetzner datacenter doesn't.7 With that scope stated: AWS charges about $0.09 per gigabyte (after 100 GB/month free); Hetzner's overage runs about €1, roughly $1.20, per terabyte — three orders of magnitude apart per unit, landing around 75× at the first paid tier (and still ~40× even at AWS's deepest volume discounts). On raw compute the gap is smaller but still large: a bare server is roughly 2–5× cheaper than the on-demand cloud equivalent, narrowing to about 2× if you commit to AWS's multi-year reserved pricing.8 These multiples are not a rounding error. They are the load-bearing fact under every "the cloud is a rip-off" argument, and we are going to take that argument seriously in a moment.
But notice where on the curve the savings live. The bottom rung's cheapness only pays off if you're running enough traffic and enough compute to amortize the fixed cost and the labor. There's a crossover point — and the uncomfortable truth for most readers is that their site will never reach it. Below the crossover, the "expensive" managed rung is actually the cheaper one once you count everything, because the thing the lower rung makes you spend isn't dollars. It's you.
Part 4Who carries the pager?
"Control" is a flattering word. Here is its less flattering synonym: responsibility. And responsibility has a specific, visceral form — the 3am page, when something breaks and someone has to get up and fix it.
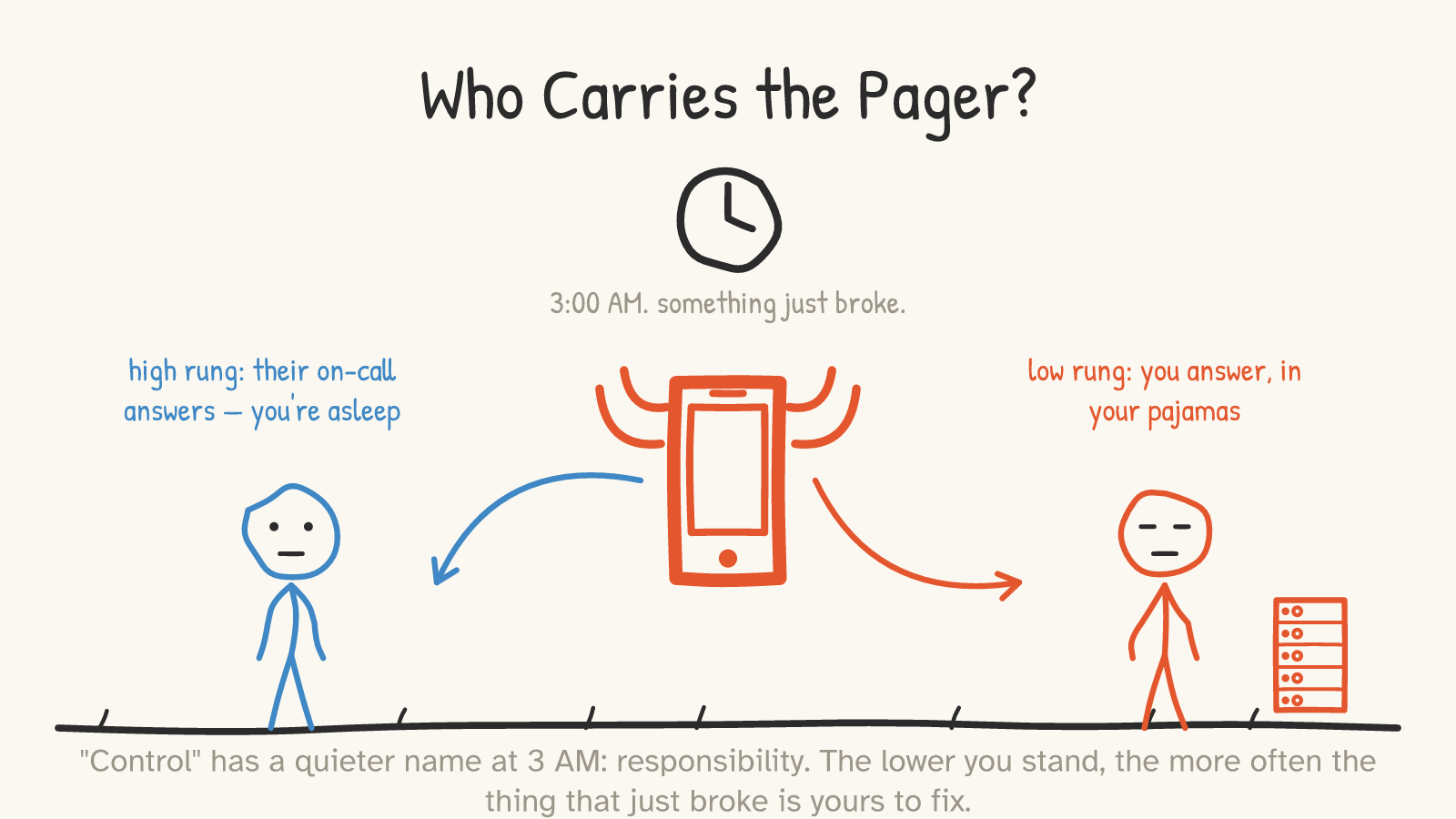
The higher your rung, the more likely that someone is a stranger on a payroll you don't manage. A Squarespace database falling over at 3am is Squarespace's emergency; you're asleep. A bare server you rent and run falling over at 3am is your emergency, in your pajamas, SSH'd into a box while the world's down. Every rung you descend moves the pager closer to your own nightstand. That's not a metaphor for the trade — it is the trade, made concrete.
Now, the honest objection in the other direction, because it's real and it cuts:
“The cloud isn't more reliable — the cloud is a single point of failure for the whole internet. One bad config push at Fastly took down Reddit, the NYT, GitHub, and Amazon for an hour. AWS's us-east-1 falls over and half the web goes with it. Concentrating everything in three companies is the fragility, not the safety.”
True, and worth sitting with. A single Fastly configuration change in June 2021 caused about 85% of its network to return errors, blanking a huge slice of the web for roughly an hour; AWS's us-east-1 region has had genuinely bad days too (the December 2021 outage cascaded across the internet).9 Concentration risk is real, and the major clouds running roughly two-thirds of the market between them is a legitimate thing to worry about.10 But the conclusion most people draw from this is backwards. The lesson isn't "so run it yourself." A lone operator running a single box — no redundant power, no failover, no one but themselves on call — is structurally unlikely to beat a cloud provider's uptime, however memorable the cloud's rare bad days are. The big outages are memorable precisely because they're rare; the small operator's outages are forgettable precisely because they're routine. Going down the ladder doesn't remove the outage. It just makes the outage yours. The threshold question is simple and brutal: can you, personally, beat the cloud's uptime? A handful of teams genuinely can. Most cannot.
Part 5"But the cloud is a rip-off"
Now the big one. The strongest argument against the whole upper half of the ladder, in its strongest form, made by serious people:
“You're paying rent on a markup. The managed rungs charge anywhere from 2× to dozens of times what the raw materials cost, and a big slice of that gap is margin you're funding — AWS's own filings put its operating margin somewhere between 27% and 37% depending on the year, and it's been climbing. 37signals, the company behind Basecamp, did the math, left the cloud, and is saving millions. 'Convenience' is the word they use to sell a markup to people who never learned to read a Linux manual.”
I'm not going to wave this away, because the evidence behind it is solid and I'd lose your trust if I pretended otherwise.

37signals is the real receipt, so let's read it honestly. They were spending about $3.2 million a year on AWS — and that's with the discounts. They bought roughly $700,000 of their own servers, moved seven applications (including their email product, HEY) onto them, and cut their annual cloud bill to about $1.3 million. They saved roughly $2 million in 2024 alone and recouped the hardware cost inside the first year — both figures from 37signals, corroborated by contemporaneous press. They also project savings topping $10 million over five years, but that one is their own forward estimate (revised up from an earlier ~$7M figure), not money in the bank, and it assumes nothing major changes.11 All of it, they say, without adding headcount. Their founder, DHH, has been blunt about it: renting computers, he wrote, "is (mostly) a bad deal for medium-sized companies like ours with stable growth."12
All true. And large. The markup is real, the savings are real, and anyone who tells you otherwise is selling their side. So the question isn't whether 37signals saved money. They did. The question is the one hiding in DHH's own sentence — the part with the parentheses and the "like ours."
Part 6Read the fine print
Look again at what made that win possible, because the conditions are the whole story.

37signals' repatriation worked because of three things, all true at once: their load was steady and predictable (mature products, no viral spikes — they could "dramatically over-provision" and still come out ahead); they already had an operations team capable of running hardware, so the migration added no headcount; and they deliberately avoided the sticky, proprietary managed services, building on portable pieces so the exit was clean.13 Take away any one of those and the math wobbles. Take away all three — which describes most people reading this — and it collapses.
This is where I have to concede the single most legitimate hole in their public numbers: they report flat headcount, but they've never published the incremental labor hours. Owning hardware means firmware updates, failed-drive swaps, capacity planning, colo coordination — real work that "we didn't hire anyone" doesn't fully capture.14 Their savings are almost certainly real and large; they are just not a clean, labor-free number, and the honest reader should hold that asterisk.
And there's a second piece of fine print that flips the lock-in worry on its head. The thing that actually traps you in the cloud usually isn't the egress fee — it's the proprietary services. A site you "lift and shift" (your own database running on a rented VM) can leave easily. A site built deeply on a specific cloud's proprietary database, queue, and event glue is genuinely expensive to disentangle, sometimes more expensive than years of the egress fees everyone complains about.15 Regulators have started treating egress as the lock-in lever it is — the EU Data Act curbs switching fees now and phases out egress charges for switching entirely by 2027 — but the deeper trap is architectural, and you avoid it by choosing portable pieces, which is exactly the discipline 37signals had and most teams skip.16
So here's the resolution. The markup is real, but it isn't a rip-off — it's a price for a real thing: the operations team you didn't hire, the pager you don't carry, the 99.99% you didn't have to engineer, the months you spent building your product instead of racking servers. For 37signals, with their scale and their steady load and their existing ops muscle, that price stopped being worth paying, and going down a rung was the right move. That's not a refutation of the ladder. It's the ladder working exactly as advertised — they found their rung. The mistake is to take "it was right for 37signals" and turn it into "everyone should self-host," which is the same error as "everyone belongs on AWS," just pointed the other way. There is no superior rung. There is only the rung that fits.
Part 7The ego trap
Which brings us to the actual villain of this essay — not AWS, not Hetzner, not any rung. It's a feeling.
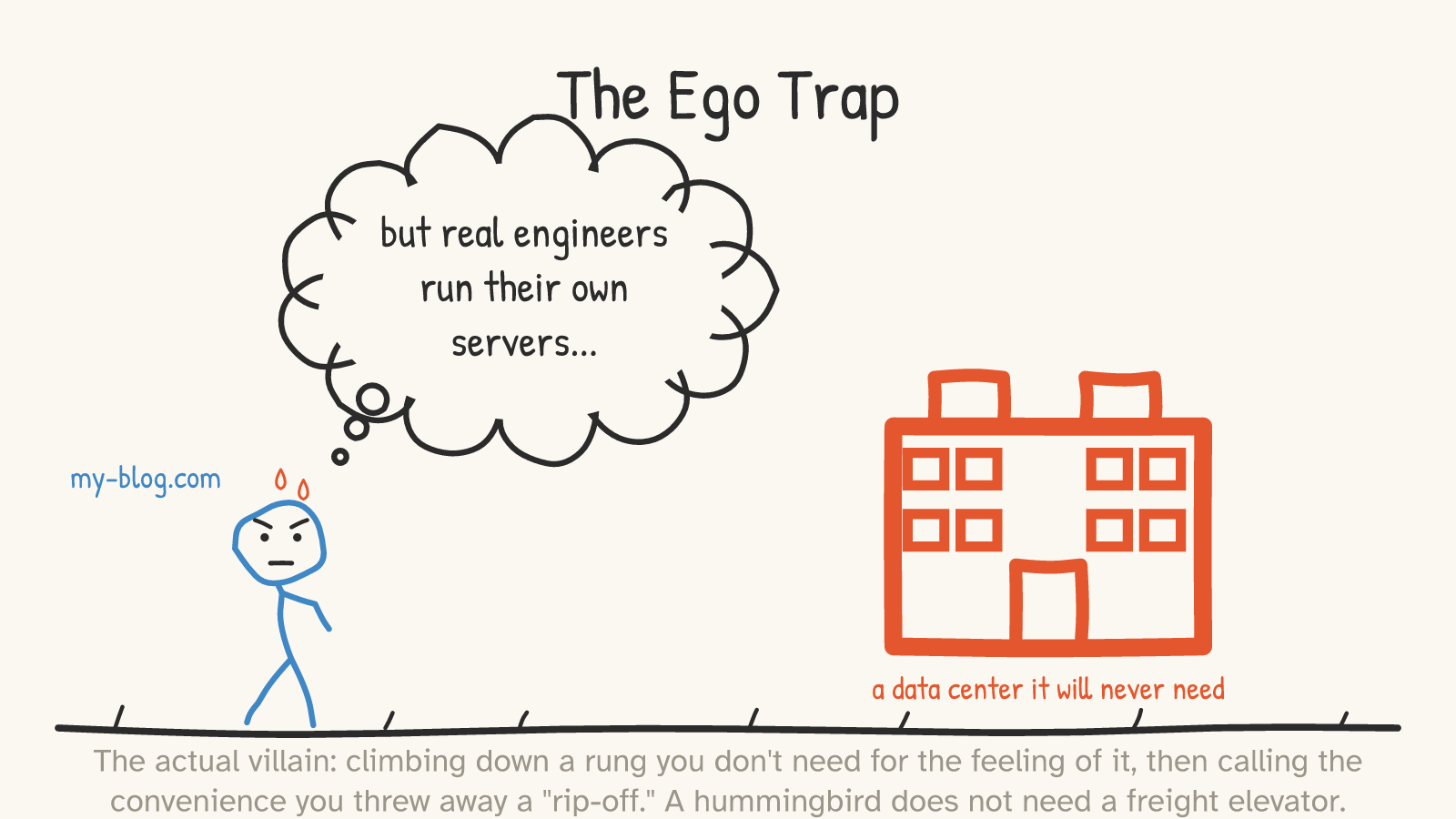
The feeling is that the lower rungs are where the real engineers live, and that paying for convenience is a little embarrassing — something you'd grow out of if you were good enough. So a person with a blog that gets two hundred visitors a month reads the 37signals story, feels the pull, and starts dragging a data center's worth of responsibility behind a website that would run, comfortably and forever, on the cheapest managed plan in existence. It's a hummingbird hauling a freight elevator.
This is just premature optimization wearing a sysadmin hat. There's a well-worn essay in this genre called "You Are Not Google" — the point being that companies cargo-cult the tools and infrastructure of hyperscale operations they will never resemble, paying enormous complexity costs for problems they don't have.17 The hosting version is identical: descending the ladder for the identity of it, then resenting the convenience you threw away and calling it a rip-off to justify the climb. The savings you're chasing are real only above a crossover you're nowhere near; below it, every hour you spend patching a server you didn't need is an hour stolen from the actual thing you were trying to build.
And — to be fair, because this trap runs both ways — there's a mirror-image version that deserves equal scorn: the inertia trap. A mature business with steady load, real revenue, and a capable ops team that stays parked on a premium managed rung for years out of habit or a vague fear of Linux, quietly paying several times what it needs to, never once checking whether it has passed the crossover. That's exactly the trap 37signals climbed out of — they weren't being macho, they were doing arithmetic. The ego trap and the inertia trap are the same mistake wearing opposite outfits: standing on the wrong rung for a reason that has nothing to do with the work in front of you.
Part 8The right rung
So where should you stand? Higher than your ego wants — and you should descend only on evidence, never on vibes.
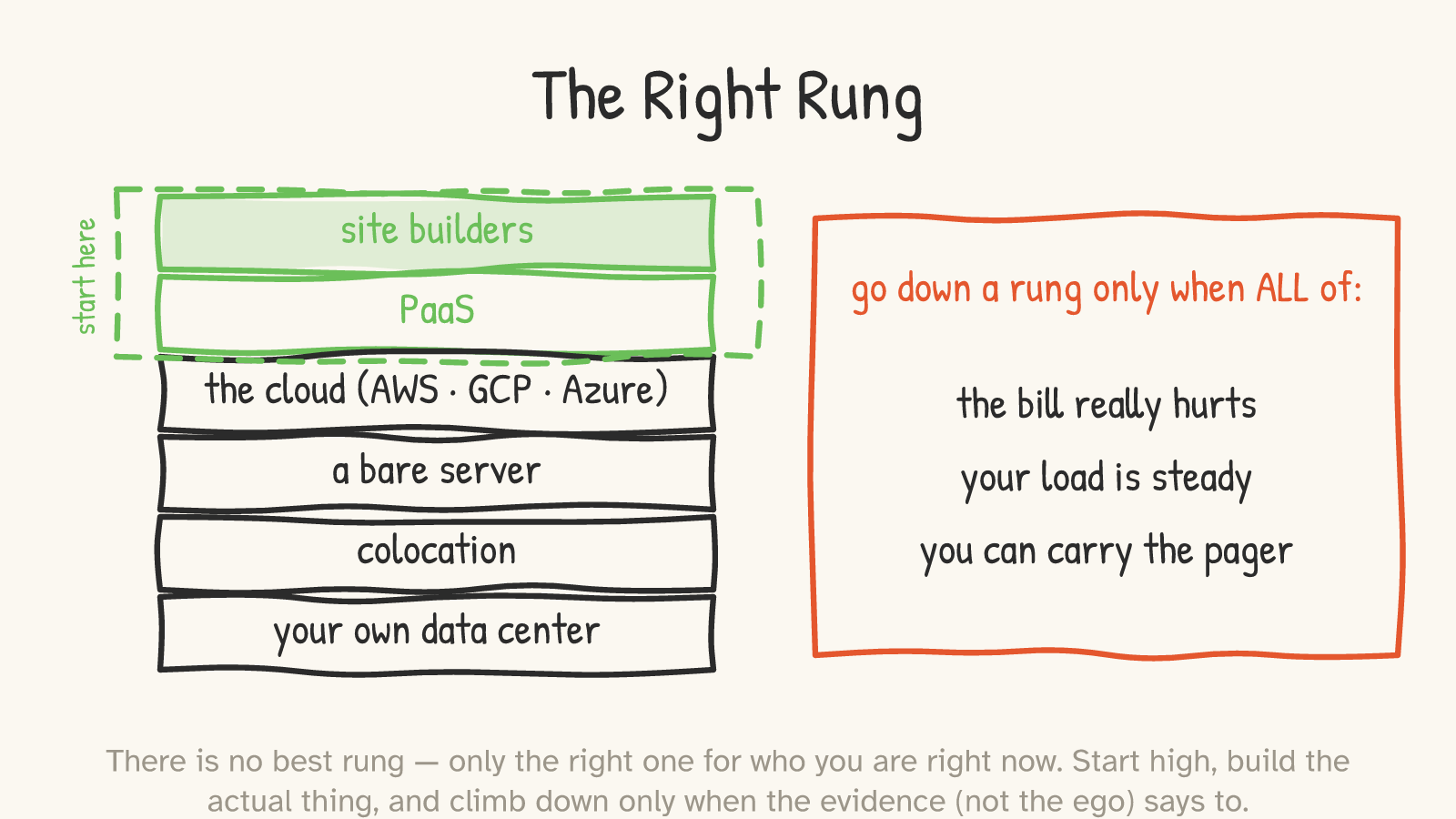
Start high. Ship the actual thing — the store, the blog, the app, the product — on a rung where the undifferentiated heavy lifting is someone else's job, and spend your scarce attention on the part only you can do. Then watch for the specific, boring signals that you've outgrown your rung — and climb down only when all three are true at once: the bill genuinely hurts (not "feels expensive" — hurts, as a real line item against real revenue); your load is steady enough that you can't just elasticity your way out of it; and you have the operational muscle to carry the pager you're about to pick up. Miss any one of those and the rung below will cost you more than it saves — in dollars, or in nights, or in the product you didn't ship because you were racking servers.
That's the whole framework. Not "the cloud is great" or "the cloud is a scam." Not "real engineers self-host" or "only fools leave Squarespace." Just: it's one ladder, your share of the work grows every rung down, the money curve crosses somewhere most sites never reach, and the right rung is a question about you — your scale, your load, your team, your goal — not a leaderboard. Stand where the trade actually favors you. For most people, most of the time, that's higher up than they'd like to admit, and there is no shame in it at all.
The person who pays for convenience and ships their idea has not lost to the person hand-compiling a kernel for a website nobody's visited yet. They've just read the ladder correctly.
Footnotes & receipts
- The shared responsibility model is published by every major cloud (AWS, Microsoft Azure, Google Cloud): a demarcation of which layers the provider operates versus the customer. At IaaS, the customer owns the guest OS, patching, applications, network/identity configuration, and data; the provider owns the hypervisor, physical hardware, and facilities. AWS's version (aws.amazon.com/compliance/shared-responsibility-model) is the canonical diagram. Tier 1 (vendor primary docs). ↩
- NIST Special Publication 800-145 (2011), "The NIST Definition of Cloud Computing," defines IaaS, PaaS, and SaaS by exactly this control boundary — IaaS: the consumer controls OS/storage/deployed apps but not the underlying infrastructure; PaaS: controls the deployed app and its config but not the OS/servers; SaaS: controls essentially nothing underneath. Tier 1 (US government standard). Placing site-builders (Squarespace/Wix/Shopify) as SaaS-grade and the bare-VPS/colo/own-DC rungs below IaaS is a definitional extension of the same control-boundary logic, not a NIST category per se. ↩
- "Pizza as a Service" is the widely shared analogy attributed to Albert Barron (LinkedIn, 2014): homemade = on-premises, take-and-bake = IaaS, delivery = PaaS, dined-out = SaaS. Tier 4 (the original post is hard to retrieve directly; it survives mostly via secondary reproductions). Used as flavor, not as the rigorous taxonomy — that's note 1–2. ↩
- Serverless / FaaS (AWS Lambda, Cloudflare Workers): you supply a function, the provider runs it with no server management, scaling to zero and billing per request + compute-time (Lambda: ~$0.20 per million requests plus per-GB-second; Cloudflare Workers: a free daily tier then ~$0.30 per million, no egress fee). It's best understood as an orthogonal billing/abstraction model that cuts across the rung ladder rather than a single rung. Tier 1 (vendor pricing/docs). ↩
- "Undifferentiated heavy lifting" is Jeff Bezos's phrase for infrastructure work that consumes engineering time without differentiating the business — provisioning, patching, backups. The concept anchored AWS's 2006 launch (paraphrased in Amazon's own 2006 materials, citing a Bezos talk); the exact phrase is cleanly documented in a Bezos talk around 2008. It became the founding rationale for AWS and has been repeated widely by AWS leadership (including CTO Werner Vogels) since. Tier 2/3 (attributed to Bezos, c.2006–2008; widely documented in cloud-computing history). ↩
- Shopify pricing (shopify.com/pricing): monthly plans Basic $29, Shopify $79, Advanced $299, Plus from ~$2,300 — the subscription itself scales ~80× across tiers. Card-processing via Shopify Payments is 2.9% + 30¢ (Basic) down to 2.25% + 30¢ (Plus), which is roughly market rate (Stripe is also 2.9% + 30¢) and therefore not a Shopify-specific markup; the genuine surcharge is the extra fee (up to ~2% on Basic) Shopify levies if you use a third-party payment gateway instead of its own. The essay cites the subscription scaling and that third-party surcharge, not the base card rate. Verify current rates before relying on them. Tier 1 (vendor pricing). ↩
- Egress multiple (~75×). AWS data-transfer-out to the internet is about $0.09/GB for the first 10 TB/month (after 100 GB/mo free), tiering down to ~$0.05/GB above 150 TB (aws.amazon.com pricing). Hetzner includes 20 TB of traffic on dedicated servers and charges about €1 (~$1.20) per additional TB (docs.hetzner.com) ≈ $0.0012/GB. $0.09 ÷ $0.0012 ≈ 75. SCOPE: this is egress only, and AWS bundles global CDN reach, SLAs, and multi-AZ redundancy that a single Hetzner datacenter does not — it is not a claim that AWS is "75× more expensive overall." Tier 1 (both vendors' pricing pages). ↩
- Compute multiple (~2–5×). A comparable always-on AWS instance runs several times the price of an equivalent Hetzner server — e.g. a Hetzner CX22 (2 vCPU, 4 GB) is about €3.79/mo, versus a similar AWS instance at roughly $15/mo on-demand: ~4–5×, narrowing to ~2× with AWS 3-year reserved/savings pricing. (AWS's cheaper burstable instances like t3.small list lower but throttle under sustained load, so they aren't a clean like-for-like for a steady workload.) SCOPE: raw compute only; excludes managed-service value, elasticity, and operations. Tier 1/3 (vendor pricing + aggregators over published rates). ↩
- Concentration outages. The Fastly outage of June 8, 2021 stemmed from a single customer configuration change and took roughly 85% of its network offline for about an hour, blanking Reddit, the NYT, GitHub, Amazon and others (Fastly post-mortem, Tier 2). AWS's us-east-1 region has had multiple high-impact multi-hour outages (e.g. December 7, 2021) that cascaded across dependent services (AWS post-mortems + press, Tier 2/3). The July 2024 CrowdStrike/Microsoft event was a software-update failure, not a cloud-infrastructure outage — included only as context, not as a cloud-reliability data point. ↩
- Market concentration: the top three cloud providers (AWS ~33%, Azure ~24%, Google ~11% — roughly two-thirds combined) held the majority of the global market as of 2023 (Canalys/IDC estimates); shares shift year to year, and because many "independent" PaaS providers themselves run atop these clouds, the true single-point-of-failure concentration is higher than the headline two-thirds. Tier 3. ↩
- 37signals figures, from the company's own posts (world.hey.com / basecamp.com/cloud-exit) and contemporaneous press (The Register, Oct 2024): prior AWS spend ~$3.2M/yr (with reserved-instance discounts); ~$700k spent on Dell hardware, "recouped" within the first year; 2024 cloud bill cut to ~$1.3M; ~$2M saved in 2024; projected savings now topping ~$10M over five years (revised up from an earlier ~$7M estimate). An earlier 2023 post cited ~$600k of hardware and a ~$1.5M/yr estimate; the figures here use the most current (Oct 2024) numbers. Tier 2 (company's own account) + Tier 3 (press). ↩
- DHH quote, "Renting computers is (mostly) a bad deal for medium-sized companies like ours with stable growth," as quoted by InfoWorld (Nov 2022) reporting on 37signals' cloud exit. The "(mostly)" and "like ours" are load-bearing and quoted intact. Tier 3 (journalistic quotation of the author). ↩
- The conditions that made 37signals' repatriation work — steady, predictable load; a pre-existing in-house ops team (migration "without adding any new staff"); deliberate avoidance of proprietary managed services for a clean exit; colocation via Deft, storage via Pure Storage — are described across their own posts. Tier 2. ↩
- The labor-hours caveat: critics (notably InfoWorld's Matt Asay, Nov 2022) argued 37signals' analysis omits the incremental operational labor of owning hardware and leans on conditions (stable load, available reserved-instance discounts) that don't generalize. 37signals reports flat headcount but has not published an audit of incremental hours; this is the strongest unresolved gap in the public numbers. Tier 3. ↩
- Lock-in via proprietary services vs. egress: "lift-and-shift" workloads (e.g. your own Postgres on a VM) are cheap to move; deeply cloud-native workloads (proprietary managed databases, queues, event glue) can be very expensive to migrate — often exceeding the egress fees that get more attention. Practitioner/analyst consensus; Tier 3. ↩
- EU Data Act (Regulation (EU) 2023/2854): published December 2023, applicable from 12 September 2025. During a transitional period switching charges (including for data egress) must be cost-based only; from 12 January 2027 the egress charges incurred during provider switching are eliminated entirely (this concerns switching, not all ongoing data transfer). EU-only. Cited as evidence that even regulators treat egress as a lock-in lever. Tier 1 (EU legal text, eur-lex.europa.eu). ↩
- "You Are Not Google" — Oz Nova, bradfieldcs.com (2017): the argument that organizations cargo-cult the tools of hyperscale companies at scales where the complexity is pure cost. Cited as the canonical statement of the premature-scaling mistake the "ego trap" mirrors. Tier 4 (practitioner essay). The widely repeated "~90% of sites get under 100 visits/day" statistic is not used here because it could not be traced to a primary source. ↩